
In immer volatileren, unsichereren, komplexen und vieldeutigeren Märkten und Umfeldern, wird gerade für große und entsprechend starre Organisationen in Zukunft die Anpassungsfähigkeit immer wichtiger. Oder mit den etwas drastischeren Worten von Jack Welch: „If the rate of change on the outside exceeds the rate of change on the inside, the end is near.“ Nun wollen also alle agil werden, ihre Supertanker agilisieren und ihre Organisationen transformieren. Auf Ebene des einzelnen Teams scheint auch schnell alles klar: klein, schlagkräftig und cross-funktional soll es sein, end-to-end verantwortlich und selbstorganisiert entscheiden mit einem Product-Owner als Visionär und Richtungsgeber. Was aber wenn die Produkte viel größer sind und gefühlt sowieso alles mit allem irgendwie zusammenhängt und also viele Teams koordiniert werden müssen? Dann schlägt die Stunde von Skalierungsframeworks wie dem Scaled Agile Framework (SAFe), Large Scale Scrum (LeSS) oder Nexus. Zu früh meistens, weil die technischen Schulden der Vergangenheit, die hohe Kopplung und die monolithischen Architekturen, dadurch akzeptiert und tendenziell nur verwaltet anstatt reduziert werden. Kurz gesagt: Entkopplung vor Skalierung.
Jahr für Jahr zeigt der Chaos-Report der Standish-Group ein ähnliches Bild: Je größer ein Projekt, desto geringer die Erfolgswahrscheinlichkeit. Auch wenn agile Projekte gegenüber Wasserfall-Projekten eine deutlich höhere Erfolgswahrscheinlichkeit haben, diese Tendenz bleibt auch hier erhalten: Je größer, desto riskanter. Zusammengefasst sieht das dann beispielsweise im Chaos-Report 2015 so aus (vergleiche auch den zugehörigen Artikel bei InfoQ):
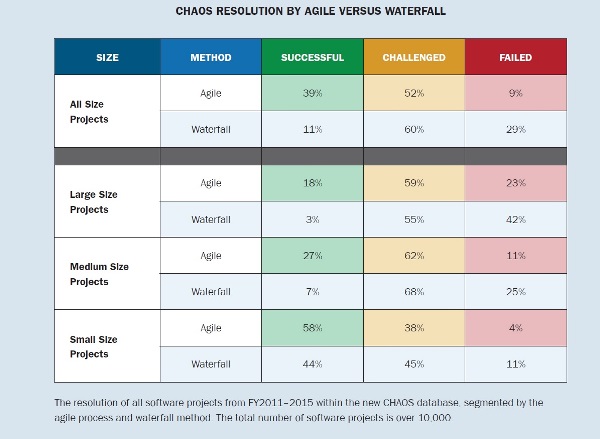
Da für viele Organisationen lange Jahre Anpassungsfähigkeit keine entscheidende Rolle spielte, sondern eher die Effizienz im Vordergrund stand, tendieren IT-Landschaften aufgrund vermuteter Skaleneffekte eher zu großen monolithischen Architekturen. Selbst wenn dieses Monolithen in verschiedene Schichten und Komponenten logisch unterteilt sind, ihre hohe Kopplung erfordert dennoch ein koordiniertes Vorgehen zur Weiterentwicklung, also gemeinsame Planung, viele Abstimmungen, gemeinsamer Test und gemeinsame Auslieferung in eine Produktionsumgebung. Da diese Monolithen ihrerseits mit anderen Monolithen und Systemen über Schnittstellen verbunden sind, sind dann für solche Cluster oft nur zwei bis drei große Releases pro Jahr möglich. Und gemäß den Ergebnissen des Chaos-Reports entsprechend riskant.
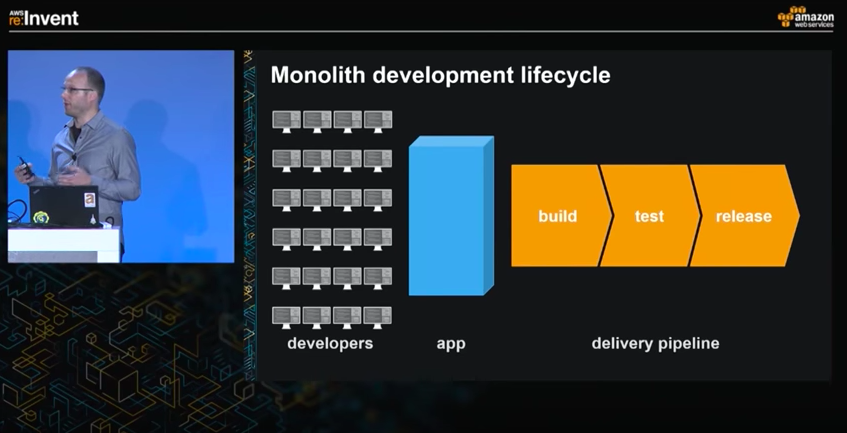
Daran ändert auch Agilität auf Teamebene mit entsprechenden Skalierungsframeworks nichts. Die historisch gewachsenen Abhängigkeiten werden einfach mehr oder weniger unhinterfragt übernommen und anders koordiniert. Auch Amazon hatte interessanterweise genau dieses Problem, wie Rob Brigham, AWS senior manager for product management, in seinem Vortrag bei re:invent 2015 selbst zugibt: „If you go back to 2001 the Amazon.com retail website was a large architectural monolith. Now, don’t get me wrong. It was architected in multiple tiers, and those tiers had many components in them, but they’re all very tightly coupled together, where they behaved like one big monolith.“ Durch konsequentes Refactoring ihres Monolithen in kleine Services mit definierten (und versionierten) Schnittstellen zur Entkopplung, automatisierten Tests gegen diese APIs und einer hoch-automatisierten Deployment-Engine (Apollo) können die Two-Pizza-Teams seither weitestgehend unabhängig Anpassungen schnell ausliefern (und taten das in den ersten zwölf Monaten nach Einführung von Apollo auch 50 Millionen mal, also mehr als einmal pro Sekunde, wie Werner Vogels, CTO Amazon, stolz berichtet). Ein schönes Beispiel für das Prinzip Entkopplung vor Skalierung.


